3 things today: Let’s talk about Survivorship Bias.
Why do we read and reread books/articles like “The Morning Habits of Successful People” or “The Six Characteristics All Billionaires Have in Common”? How many of these articles have you clicked on?
We love the idea that by learning about our idols, we’ll be able to emulate their success. A quick Google search of “Successful founders who dropped out of college,” gives names such as Steve Jobs and Mark Zuckerberg as all examples of entrepreneurs who had an idea, took a leap, and became successful.
But by equating their success to hard work alone, we ignore a very important fact: for every successful college dropout, there are hundreds, if not thousands, who weren’t as lucky.
The founders we put on pedestals worked hard, but there were also many circumstantial events that paved their way to success. In fact, research shows the majority of the United States’ most successful businesspeople graduated college – 94%, to be exact.
1) Better and cooler products don’t necessarily succeed – check TiVO, which is still barely alive
2) Don’t neglect external factors that influence success – see how Skechers kicked Adidas from top position
3) Just because you don’t hear you customer complain doesn’t mean they are happy – many customers leave before they complain of their unhappiness
You must consider the other variables not immediately visible to you to avoid the survivorship bias.
And how do I really know you are conscious? This is the problem of solipsism. I know your brain is very similar to mine as you look like a human, sound like one and give an expression of someone with brain like other humans. By mathematical induction then, there is a perfectly reasonable inference that you too are conscious.
Some 10,000 laboratories worldwide are pursuing distinct questions about the brain and consciousness across a myriad of scales and in a dizzying variety of animals and behaviours. According to most computer scientists, consciousness is a characteristic that emerges from of technological developments. Some believe that consciousness involves accepting new information, storing and retrieving old information and cognitive processing of it all into perceptions and actions. If that’s right, then one day machines will indeed be the ultimate consciousness. They’ll be able to gather more information than a human, store more than many libraries, access vast databases in milliseconds and compute all of it into decisions more complex, and yet more logical, than any person ever could.
Consciousness could be explained by “integrated information theory,” which asserts that consciousness is a product of structures, such as a brain, that can store a large amounts of information, have a critical density of interconnections and thus enable many informational feedback loops. This theory provides a means to assess degrees of consciousness in people, animals (lesser degree than humans) and even machines/programs (for example, IBM Watson and Google’s self-taught visual system). It proposes a way to measure it in a single value called Φ (phi) and helps explain why certain relatively complicated neural structures don’t seem critical for consciousness. For example, the cerebellum, which encodes information about motor movements, contains a huge number of neurons, but doesn’t appear to integrate the diverse range of internal states that the prefrontal cortex does.
The more distinctive the information (of the system), and the more specialised and integrated the system is, the higher its Φ (and anything with a Φ>0 possesses at least a shred of consciousness). Over the past few years, this theory has become increasingly influential and is championed by the eminent neuroscientist Christof Koch. The problem is that even though Φ promises to be precise, it’s so far impossible to use it for practical calculations related to human or animal brains, because an unthinkably large number of possibilities would have to be evaluated.
Accordingly, consciousness is a property of complex systems that have a particular “cause-effect” connections. If you were to build a computer that has the same circuitry as the brain, this computer would also have consciousness associated with it. It would feel like something to be this computer, like each human does. Hofstadter’s Mind’s I has a collection of essays about mind (an emerging property of brain function) and how feedback loops are essential for this emergence.
Another viewpoint on consciousness comes from quantum theory, the most profound and thorough theory about nature of things. According to the orthodox Copenhagen Interpretation, consciousness and the physical world are complementary aspects of the same reality. When a person observes, or experiments on, some aspect of the physical world, that person’s conscious interaction causes discernible change. Since it takes consciousness as a given and no attempt is made to derive it from physics, the Copenhagen theory postulates that consciousness exists by itself but requires brains to become real. This view was popular with the pioneers of quantum theory such as Niels Bohr, Werner Heisenberg and Erwin Schrödinger.
The interaction between consciousness and matter leads to paradoxes that remain unresolved after 80 years of debate. A well-known example of this is the paradox of Schrödinger’s cat, in which a cat is placed in a situation that results in it being equally likely to survive or die – and the act of observation itself is what makes the outcome certain.
Modern quantum physics views of consciousness have parallels in ancient philosophy. For example, Copenhagen theory is similar to the theory of mind in Vedanta – in which consciousness is the fundamental basis of reality, on par with the physical universe. On the other hand, England’s theory resembles Buddhism as Buddhist hold that mind and consciousness arise out of emptiness or nothingness.
A strong evidence in favour of Copenhagen theory is the life of Indian mathematician Srinivasa Ramanujan, who died in 1920 at the age of 32. His notebook, which was lost and forgotten for about 50 years and published only in 1988, contains several thousand formulas, without proof in different areas of mathematics, that were well ahead of their time. Furthermore, the methods by which he found formulas remain elusive. He claimed they were revealed to him by a goddess while he was asleep.
Thinking deeper about consciousness leads to the question of how matter and mind influence each other. Consciousness alone cannot make physical changes to the world, but perhaps it can change probabilities in the evolution of life and thus quantum processes? The act of observation can freeze and even influence atoms’ movements, as shown in 2015. This may very well be an explanation of how matter and mind interact.
You keep on hearing about AI is bad and once AGI is around, it will kill us off – paperclip maximization principle is a telling example? Check the below tidbits pushing the envelop.
Music
Historically, people line up to attend concerts of famous artists. Now, there is AI that generates pure gold jazz or what sounds like a mix of jazz and classic. Would you line up to hear these pieces? Would you still line up if you didn’t know whether it’s an algorithm or a human?
Fiction
Do you like Harry Potter? What about this Harry Potter? This algorithm learnt from the first few chapters of J.K.Rowling’s Harry Potter and created a novel of its own. Forget about J.K.Rowling, move on.
MIT researches created their AI system, which predicts human behaviour by approximating human “intuition” from myriads of data, and pitted it against human teams at data science competitions. The algorithm didn’t get the top score but it beat 615 of the 906 human teams competing. In two of the competitions, it created models that were 94% and 96% as accurate as the winning teams. Whereas the teams of humans required months to build their prediction algorithms, this algorithm trained 2-12 hours.
Cannibalism
Once virtual Adam and Eve (AI bots) were done with apples, they ate Stan, an innocent bystander (another AI bot) that happened to look like an apple.
Formula of life
OK, all the above are creepy, cool, scary, depending on your knowledge, interest and approach to life. But could these AI concepts eventually yield or create actual or natural life forms?
What Darwin’s theory talks about and what we believe is that there is clear difference between living organisms (in how they come to be and evolve) and everything else (from water vortexes to AI systems to coastal lines of England). Popular hypotheses credit a primordial soup, big bang and a colossal stroke of luck for creation of of life. Erwin Schrödinger framed life merely as physical processes in his treatise “What is Life?”.
But till now we had hard time explaining how (open) thermodynamic systems like our universe and even Earth evolved and how lifeforms evolved in them. We have answers for (close and weak open) ones. Till now.
According to Jeremy England from MIT given it a thermodynamic framing: it’s all about entropy (to create life, one has to decrease entropy). Carbon is not God. In his view, there is one essential difference between living things and inanimate chunks of carbon atoms: the former tend to be much better at capturing energy from their environment and dissipating that energy as heat. He has math formula, which indicates that when a group of atoms is driven by an external source of energy (like the sun) and surrounded by heat (like the ocean or atmosphere), it will often gradually restructure itself in order to dissipate increasingly more energy. This implies that under certain conditions, matter may acquire key physical attribute associated with life.
Now back to AI craze above. Imagine if we could introduce systems that artificially decrease entropy in AI systems as per Jeremy England’s prescriptions, near future could see a new Cambrian explosion of artificially constructed forms of life, which are….. songs, movies, fiction, ….. and perhaps new and better beings!
Bitcoin is the first example of a new form of life. It lives and breathes on the internet. It lives because it can pay people to keep it alive. It lives because it performs a useful service that people will pay it to perform. … It can’t be stopped. It can’t even be interrupted. If nuclear war destroyed half of our planet, it would continue to live, uncorrupted.
How do you know how well an industry/technology/product/.. does?
One way to check is to find out the two contextual (from economic, technological, social, …other perspectives) extremes of that industry/technology/product/…
Let’s have a go at Bitcoin/blockchain.
If you go to Etherscan, click on top menu item Tokens and then View Tokens, and if you search for “fuck,” below is the screenshot from few days ago.
This of course is just one extreme, negative one, illustrating at once absurdity, creativity and ambition one can find in crypto space. While some of those tokens are placeholders, some like FUCK Token have a website and give an impression of an upcoming product. The F-word derived tokens allude to Facebook and Ethereum. Unsurprising.
For a positive extreme, check out DeepRadiology, which employs both deep learning (Yan LeCun, father of deep learning, is their advisor) as well as blockchain to “applying the latest imaging analytic deep learning algorithm capability for all imaging modalities to optimize your facility service needs.“
DeepRadiology uses AI to process myriads of data and blockchain to store and distribute it efficiently and effectively. Both time to process, for example, a CT scan and relevant costs are an order of magnitude less than the incumbents. Everyone wins.
And while Q1 2018 was bearish for all cryptocurrencies, whether rest of 2018 will be bearish or bullish is still a question. Either way, due to maturing crypto market, more educated/pragmatic crypto investors/enthusiasts and less easy-to-get crypto, the focus is now on technology itself, which is what’s needed, in long-term.
Let’s start by setting up a context of just how much it costs to verify one Bitcoin transaction. A report on Motherboard recently calculated that the cost to verify 1 Bitcoin transaction is as much electricity as the daily consumption of 1.6 American Households. Bitcoin network may consume up to 14 Gigawatts of electricity (equivalent to electricity consumption of Denmark) by 2020 with a low estimate of 0.5GW.
There is much written about theft of Bitcoin, as people are exposed to cyber criminals, but there are also instances where people are losing their coins. In case of loss, it’s almost always impossible to recover lost Bitcoins. They then remain in the blockchain, like any other Bitcoin, but are inaccessible because it’s impossible to find private keys that would allow them to be spent again.
Bitcoin can be lost or destroyed through the following actions:
irrecoverable passwords or private keys, b) forgotten wallets,
hardware problems (hard drive containing keys dies or is damaged)
Bitcoin burning (set up a wallet with no known private key, and it can be seen online, complete with every transaction, but the funds will likely never be retrieved),
Sometimes, not only individuals but also experienced companies make big mistakes and loose their Bitcoins. For example, Bitomat lost private keys to 17,000 of their customers’ Bitcoins. Parity lost $300m of cryptocurrency due to several bugs. And most recently, more than $500 million worth of digital coins were stolen from Coincheck.
Lot Bitcoin losses also come from Bitcoin’s earliest days, when mining rewards were 50 Bitcoins a block, and Bitcoin was trading at less than 1 cent. At that time, many didn’t care if they lost their (private) keys or just forgot about them; this guys threw away his hard drive containing 7500 Bitcoins.
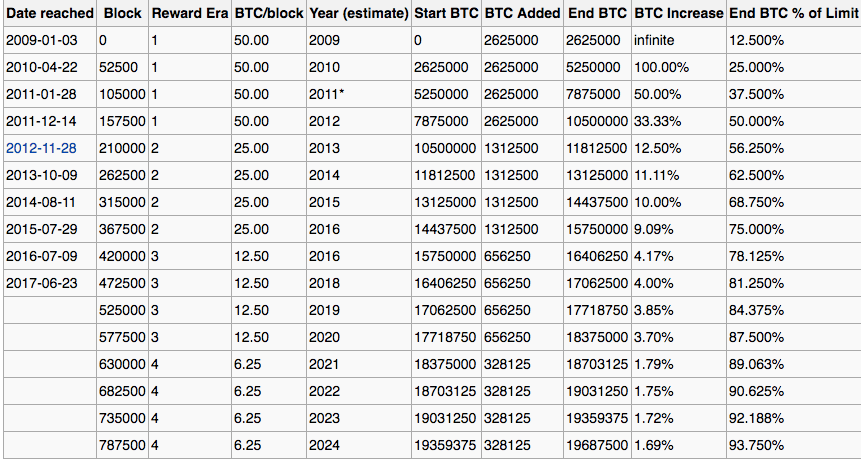
Let’s briefly analyse Bitcoin’s creation and increase of supply. The theoretical total number of Bitcoins is 21 million. Hence, Bitcoin has a controlled supply. Bitcoin protocol is designed in such a way that new Bitcoins are created at a decreasing and predictable rate. Each year, number of new Bitcoins created is automatically halved until Bitcoin issuance halts completely with a total of 21 million Bitcoins in existence.
While the number of Bitcoins in existence will never exceed 21 million, the money supply of Bitcoin can exceed 21 million due to fractional-reserve banking.
As of June 23, 2017, Bitcoin has reached a total circulation amount of 16.4 million Bitcoins, which is about 81,25% of the total amount of 21 million Bitcoins.
2017 research by Chainanalysis showed that between 2.78 million and 3.79 million Bitcoins are already lost or 17% – 23% of what’s been mined to date.
How much Bitcoin exactly has been lost? It’s a pretty tough question considering there is no definitive metric for finding the answer. A good estimate is around 25% of all Bitcoin, according to this analysis (this research concludes 30% of all coins had been lost, equating to 25% of all coins when adjusted for the current amount of coins in circulation, which can be done as bulk of lost Bitcoins originate from very early and as Bitcoin’s value has been going up, people lose their coins at a slower rate).
With advent of quantum computers, future of Bitcoin might be perilous. One researcher suggested that quantum computers can calculate the private key from the public one in a minute or two. By learning all the private keys, someone would have access to all available bitcoin. However, a more extensive research shows that in short term, impact of quantum computers will appear to be rather small for mining, security and forking aspects of Bitcoin.
It’s possible that an arms race between quantum hackers and quantum Bitcoin creators will take place. There is an initiative that already tested a feasibility of quantum-safe blockchain platform utilizing quantum key distribution across an urban fiber network.
The below image shows encryption algorithms vulnerable and secure for quantum computing.
The no-cloning theorem will make it impossible to copy and distribute a decentralized ledger of qubits (quantum units of information). As qubits can’t be copied or non-destructively read, they will act more like real coins (no issue of double-spending). Quantum Bitcoin miners might support the network by doing operations which amount to quantum error correction (which might replace current Proof-of-Work or Proof-of-Stake systems) as the use of quantum entanglement will enable all network participants to simultaneously agree on a measurement result without a proof of work system.
And while we are waiting for quantum-era Satoshi to rise, check out this THEORETICAL account of how quantum computers may potentially create Bitcoin, which also contains primers on quantum computers and Bitcoin mining.
Deep learning models can already achieve state-of-the-art results in some applications, but their capabilities are still limited. Unlike humans, deep learning models are unable to handle minor changes, and hence can only be applied for specific and narrowly defined tasks.
Consider this conversation of what might be the most sophisticated negotiation software on the planet, which occurred between two AI agents developed at Facebook:
Bob: “I can can I I everything else.”
Alice: “Balls have zero to me to me to me to me to me to me to me to me to.”
At first, they were speaking in plain old English, but researchers realized they forgot to include a reward for sticking to the language. So, the AI agents began to diverge, eventually rearranging legible words into seemingly nonsensical (but, in their perspective, highly efficient) sentences. They invented their own codewords, abbreviations, and structures.
A vanguard AI technology that can learn, recognize, and generate information on a nearly human level doesn’t exist yet, but we have taken steps toward that direction.
What are generative adversarial networks (GANs)?
Generally intelligent systems must be able to generalize from limited data and learning causal relationships. In 2016, Ian Goodfellow, a fellow at Google Brain, suggested using generative adversarial networks (GANs) as an alternative unsupervised machine learning method. This aimed to address many of the ailing points of the existing methods.
GANs consist of two deep neural networks: generator and discriminator. The generator’s goal is to create data samples that are so indistinguishable to the real ones. The discriminator’s goal is to identify which of the generator’s data samples are real and which are fake.
These two networks compete against each other in a zero-sum game (i.e. one’s loss implies another’s win). Both networks would then become stronger in a relatively short period of time.
Backpropagation is used to update the model parameters and train the neural networks. Over time, the networks learn many features of the provided data. To create realistic forged samples, the generator needs to learn the data’s features and patterns, while the discriminator does the same to correctly distinguish between real and fake samples.
GANs are thus able to overcome the above weaknesses by training (i.e. playing) neural networks against each other, thus learning from each other (which necessitates less data) and eventually performing better in a broader range of problems.
The video game industry is the first area of entertainment to start seriously experimentingusing AI to generate raw content. There’s a huge cost incentive to invest in video game development automation given the US$300 million+ budget of modern AAA video games.
GANs have also been used for text, with less success⏤a bot developed to speak like Friedrich Nietzsche started to speak in a manner similar to the philosopher, but the sentences did not make sense. GANs for voice applications are able to reproduce a given text string to life-like voices with approximately 20 minutes of voice samples, such as these popular impersonations of American presidents Donald Trump and Barack Obama. In the near future, videos can likely be generated just by providing a script.
Goodfellow and his colleagues used GANs for image generation, recognition, and classification by teaching one of the networks to create images of handwritten digits (humans were not able to distinguish real handwritten digits). They also trained a neural network to create images of objects, which humans could only differentiate (from real ones) 78.7 percent of the time. Below are some sample images of faces created entirely by deep convolutional GANs.
Despite all the above achievements, GANs still have weaknesses:
Instability (the generator and the discriminator losses keep oscillating) and non-convergence (to optimum) of the objective function in GANs
Mode collapse (this happens when the generator doesn’t produce diverse images or information)
The possibility that either the generator or the discriminator becomes too strong as compared to the others during training
The possibility that either the generator or the discriminator never learns beyond a certain point
An existential threat
Do GANs and AI in general pose an existential threat to humanity? Elon Musk thinks so. Since 2014, he has been advocating adoption of AI regulations by authorities around the world. Recently, he reiterated the urgent need to be proactive in regulation.
“AI is a fundamental risk to the existence of human civilization,” Musk tells US politicians recently.
His concerns stem from the rapid developments related to GANs, which might push humanity toward the inception of artificial general intelligence. While AI regulations may serve as safeguards, AI is still far from the fictitious depictions seen frequently in Hollywood sci-fi movies.
(By the way, Facebook ultimately opted to require its negotiation bots to speak in plain old English.)
Deep learning is a new name for an approach to AI called neural networks, which have been going in and out of fashion for more than 70 years. Neural networks were first proposed in 1944 by Warren McCullough and Walter Pitts, two researchers who moved to MIT in 1952 as founding members of what’s sometimes called the first cognitive science department.
Neural networks were a major area of research in both neuroscience and computer science until 1969, when, according to computer science lore, they were killed off by the MIT mathematicians Marvin Minsky and Seymour Papert, who became co-directors of the new MIT Artificial Intelligence Laboratory in 1970.
Neural networks are a means of doing machine learning, in which a computer learns to perform specific tasks by analysing training examples. Usually, these examples have been hand-labeled in advance. An object recognition system, for instance, might be fed thousands of labeled images of cars, houses, coffee cups, and so on, and it would find visual patterns in the images that consistently correlate with particular labels.
Modelled loosely on the human brain, a neural net consists of thousands or even millions of simple processing nodes that are densely interconnected. Most of today’s neural nets are organised into layers of nodes, and they’re “feed-forward,” meaning that data moves through them in only one direction. An individual node might be connected to several nodes in the layer beneath it, from which it receives data, and several nodes in the layer above it, to which it sends data.
Architecture and main types of neural networks
A typical neural network contains a large number of artificial neurons called units arranged in a series of layers.
Input layer contains units (artificial neurons) which receive input from the outside world on which network will learn, recognise about or otherwise process.
Output layer contains units that respond to the information about how it learned a task.
Hidden layers are situated between input and output layers. Their task is to transform the input into something that output unit can use in some way.
Perceptron has two input units and one output unit with no hidden layers, and is also called single layer perceptron.
Radial Basis Function Network are similar to the feed-forward neural network except radial basis function is used as activation function of these neurons.
Multilayer Perceptron networks use more than one hidden layer of neurons. These are also known as deep feed-forward neural networks.
Recurrent Neural Network’s (RNN) hidden layer neurons have self-connections and thus possess memory. LSTM is a type of RNN.
Hopfield Network is a fully interconnected network of neurons in which each neuron is connected to every other neuron. The network is trained with input pattern by setting a value of neurons to the desired pattern. Then its weights are computed. The weights are not changed. Once trained for one or more patterns, the network will converge to the learned patterns.
Boltzmann Machine Network are similar to Hopfield network except some neurons are for input, while others are hidden. The weights are initialized randomly and learn through back-propagation algorithm.
Convolutional Neural Network(CNN) derives its name from the “convolution” operator. The primary purpose of Convolution in case is to extract features from an input image/video. Convolution preserves the spatial relationship between pixels by learning about image/video features using small squares of input data.
Of these, let’s have a very brief review of CNNs and RNNs, as these are the most commonly used.
CNN
CNNs are ideal for image and video processing.
CNN takes a fixed size input and generate fixed-size outputs.
Use CNNs to break a component (image/video) into subcomponents (lines, curves, etc.).
CNN is a type of feed-forward artificial neural network – variation of multilayer perceptrons, which are designed to use minimal amounts of preprocessing.
CNNs use connectivity pattern between its neurons as inspired by the organization of the animal visual cortex, whose neurons are arranged in such a way that they respond to overlapping regions tiling the visual field.
CNN looks for the same patterns on all the different subfields of the image/video.
RNN
RNNs are ideal for text and speech analysis.
RNN can handle arbitrary input/output lengths.
Use RNNs to create combinations of subcomponents (image captioning, text generation, language translation, etc.)
RNN, unlike feedforward neural networks, can use its internal memory to process arbitrary sequences of inputs.
RNNs use time-series information, i.e. what is last done will impact what done next.
RNN, in the simplest case, feed hidden layers from the previous step as an additional input into the next step and while it builds up memory in this process, it is not looking for the same patterns.
A type of RNN are LSTM and GRU. The key difference between GRU and LSTM is that a GRU has two gates (reset and update) whereas an LSTM has three gates (input, output and forget). GRU is similar to LSTM in that both utilise gating information to solve vanishing gradient problem. GRU’s performance is on par with LSTM, but computationally more efficient.
GRUs train faster and perform better than LSTMs on less training dataif used for language modelling.
GRUs are simpler and easier to modify, for example adding new gates in case of additional input to the network.
In theory, LSTMs remember longer sequences than GRUs and outperform them in tasks requiring modelling long-distance relations.
GRUs expose complete memory, unlike LSTM
It’s recommended to train both GRU and LSTM and see which is better.
Deep learning frameworks
There are several frameworks that provide advanced AI/ML capabilities. How do you determine which framework is best for you?
The below figure summarises most of the popular open source deep network repositories. The ranking is based on the number of stars awarded by developers in GitHub (as of May 2017).
Google’s TensorFlow is a library developed at Google Brain. TensorFlow supports a broad set of capabilities such as image, handwriting and speech recognition, forecasting and natural language processing (NLP). Its programming interfaces includes Python and C++ and alpha releases of Java, GO, R, and Haskell API will soon be supported.
Caffe is the brainchild of Yangqing Jia who leads engineering for Facebook AI. Caffe is the first mainstream industry-grade deep learning toolkit, started in late 2013. Due to its excellent convolutional model, it is one of the most popular toolkits within the computer vision community. Speed makes Caffe perfect for research experiments and commercial deployment. However, it does not support fine granularity network layers like those found in TensorFlow and Theano. Caffe can process over 60M images per day with a single Nvidia K40 GPU. It’s cross-platform and supports C++, Matlab and Python programming interfaces and has a large user community that contributes to their own repository known as “Model Zoo.” AlexNet and GoogleNet are two popular user-made networks available to the community.
Caffe 2 was unveiled in April 2017 and is focused on being modular and excelling at mobile and at large scale deployments. Like TensorFlow, Caffe 2 will support ARM architecture using the C++ Eigen library and continue offering strong support for vision-related problems, also adding in RNN and LSTM networks for NLP, handwriting recognition, and time series forecasting.
MXNet is a fully featured, programmable and scalable deep learning framework, which offers the ability to both mix programming models (imperative and declarative) and code in Python, C++, R, Scala, Julia, Matlab and JavaScript. MXNet supports CNN and RNN, including LTSM networks and provides excellent capabilities for imaging, handwriting and speech recognition, forecasting and NLP. It’s considered the world’s best image classifier, and supports GAN simulations. This model is used in Nash equilibrium to perform experimental economics methods. Amazon supports MXNet, planning to use it in existing and upcoming services whereas Apple is rumorred to be also using it.
Theano architecture lacks the elegance of TensorFlow, but provides capabilities like symbolic API supports looping control, so-called scan, which makes implementing RNNs easy and efficient. Theano supports many types of convolutions for hand writing and image classification including medical images. Theano uses 3D convolution/pooling for video classification. It can process natural language processing tasks, including language understanding, translation, and generation. Theano supports GAN.
DISCLAIMER: This is a perpetual WORK-IN-PROGRESS and thus doesn’t claim to be comprehensive but rather to serve as a guide. We welcome any feedback, especially suggestions for improvement from companies who have done an (successful) ICO. Suggested approaches and numbers in the checklist are not carved in stone/truth but guidelines. Lastly, information (names of people, entities, numbers) not present in the checklist will be shared only based on explicit interests and requests on case by case basis. USE all the info below and in the checklist at your own risk and for your benefit and guidance.
Context and mania
The amount of money being raised through Initial Coin Offerings (ICO) has quintupled since May 2017. The four largest ICOs to date – Filecoin ($206M), Tezos ($232M), EOS ($180M), and Bancor ($154M) – have raised $772 million between them. We are experiencing a bubble, but not as crazy when compared to $8 trillion over market capitalisation during the dot.com era. With proliferation of ICOs and tokens, era of zombie tokens is also upon us. You can check new and ongoing ICOs rated here.
Coindesk: Over $3.5 billion dollars have been raised to date via ICOs
It was a hot summer with $462M raised in June 2017, $575M in July 2017, and the peak was reached in September 2017 with a whopping $663M of ICO funding.
In view of ICO and blockchain mania, SEC has issued guidelines and statements. SEC has already charged two ICOs with fraud. Tezos has been hit with two class action lawsuits. Singapore’s MAS and Malaysia’s SC have already highlighted risks and issued preliminary guidelines related to ICOs. Other regulators will also be tightening up compliance and regulatory guidelines further in next few months. Projects such as SAFT (Simple Agreement for Future Tokens) help navigate US laws.
OK, so there are six main aspects to an Initial Coin Offering:
Team/Advisors
Technology
Product/Platform
Business Model
Legal/Regulation
Marketing/Roadshow and Investor Relations
And most companies differentiate between pre-ICO, ICO and post-ICO stages of activities.
Poker is a game with imperfect information. Imperfect-information games model settings where players have private information. Huge progress has been made in solving such games over the past 20 years, especially since the Annual Computer Poker Competition was established in 2006. Before 2006, general-purpose linear programming solvers (example) and sequence-form representation (example) were used to solve small variants of poker or coarse abstractions of two-player limit Texas Hold’em.
Since 2006, two more scalable equilibrium-finding algorithms and problem representations have been developed for two-player zero-sum games. One family is based on smoothed gradient descent algorithms and a decomposed problem representation. The other family, counterfactual regret minimisation (CFR), is based on a form of self-play using no-regret learning, adapted so that regret updates can be computed at each information set separately, instead of requiring regrets to be updated for entire game strategies.
Best available guarantees for CFR require ~1/ε 2 iterations over the game tree to reach an ε-equilibrium, that is, strategies for players such that no player can be exploited by more than ε by any strategy. The gradient-based algorithms require only ~1/ε or ~log(1/ε) iterations. The latter approach matches the optimal number of iterations required. On the other hand, more effective sampling techniques have been developed for CFR than for the gradient-based algorithms, so quick approximate iterations can be used.
How to solve imperfect-information games
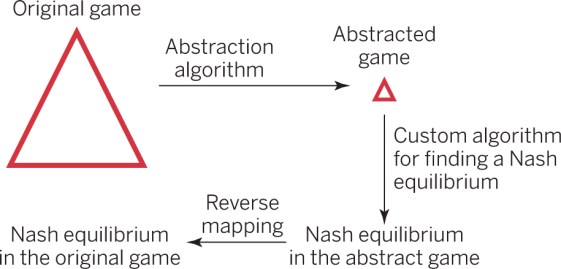
Currently, the main approach for solving imperfect-information games is shown in the image below. First, the game is abstracted to generate a smaller but strategically similar game, reducing it to a size that can be tackled with an equilibrium finding algorithm.
Then, the abstract game is solved for equilibrium or near-equilibrium. Nash equilibrium defines a notion of rational play, i.e. it’s a profile of strategies, one per player, such that no player can increase his/her expected payoff by switching to a different strategy. A strategy for a player states for each information set where it is the player’s turn, the probability with which the player should select each of his/her available actions.
An information set is a collection of game states that cannot be distinguished by the player whose turn it is because of private information of other players. Finally, the strategies from the abstract game are mapped back to the original game.
Two main kinds of abstraction are used. One is information abstraction, where it is assumed in the abstract game that a player does not know some information that he/she actually knows. Lossless abstraction algorithms yield an abstract game from which each equilibrium is also an equilibrium in the original game, and typically reduce the size of poker (or other such) games by 1-2 orders of magnitude.
The second method, action abstraction, removes some actions from consideration in the abstract game, and is useful when the number of actions that a player can choose is large.
Libratus vs. top poker players
Previously, AI has beaten chess, checkers, Go, Jeopardy but managed to beat poker only in January 2017. Unlike chess or Go, poker is a game of imperfect-information and requires a different methodology to tackle it.
Libratus beat a team of four top poker professionals in Heads-up no-limit Texas hold’em, which has 6.38 × 10161 decision points. It played with each player a two-player game and collectively amassed about $1.8 million in chips. It used the above-mentioned approach of simplifying and abstracting the game, then finding an equilibrium followed by mapping the abstract game back to the original one while adding details and improving the overall strategy. Libratus includes three main parts:
Algorithm for computing (an approximate Nash equilibrium) a blueprint for the overall strategy of smaller and simpler play, using a precomputed decision tree of about 1013 decision points, instead of 10161 points in the usual game. So it starts with a simple weighted decision tree from which to select its moves depending on its hole cards and those on the board. One example of these simpler abstractions is grouping and treating similarly hands such as King-high flush and a Queen-high flush or bets of $100 or $105.
Algorithm that fleshes out the details of the strategy for earlier subgames that are reached or realised during a play, and a coarse strategy for the later rounds based on assumed realization of the earlier ones. Whenever an opponent makes a move that is not in the abstraction, the module computes a solution to this subgame that includes the opponent’s move.
Self-improver algorithm that solves potential weaknesses opponents have identified in the game’s strategy. Typically, AIs use ML to find mistakes in the opponent’s strategy and exploit them. But that also opens the AI to exploitation if the opponent shifts strategy. Instead, Libratus’ self-improver module analyses opponents’ bet sizes to detect potential holes in Libratus’ strategy. Libratus then adds these missing decision branches, computes probabilities and strategies for them, and adds them to the existing strategy.
This strategy is called the blueprint strategy.
Libratus is computationally expensive and was powered by the Bridges system, a high-performance computer that could achieve, at maximum, 1.35 Pflops. Libratus burned through approximately 19 million core hours of computing throughout the tournament In addition to beating the human experts, Libratus has also won against the previous AI champion Baby Tartanian8.
Another one, DeepStack, is an AI capable of playing Heads-up no-limit Texas Hold’em, which includes a similar algorithm, continual re-solving, but it has not been tested against top professional players.
Most of the same abstraction techniques apply for games with more than two players that are not zero-sum, but their equilibrium-finding problems are such that no polynomial-time algorithm is known. It is not even clear that finding a Nash equilibrium is the right goal in such games. Different equilibria can have different values to the players.
This AI could be used for calculating strategic decisions in the real world, such as in finance and information security.