Let’s start by setting up a context of just how much it costs to verify one Bitcoin transaction. A report on Motherboard recently calculated that the cost to verify 1 Bitcoin transaction is as much electricity as the daily consumption of 1.6 American Households. Bitcoin network may consume up to 14 Gigawatts of electricity (equivalent to electricity consumption of Denmark) by 2020 with a low estimate of 0.5GW.
There is much written about theft of Bitcoin, as people are exposed to cyber criminals, but there are also instances where people are losing their coins. In case of loss, it’s almost always impossible to recover lost Bitcoins. They then remain in the blockchain, like any other Bitcoin, but are inaccessible because it’s impossible to find private keys that would allow them to be spent again.
Bitcoin can be lost or destroyed through the following actions:
- irrecoverable passwords or private keys, b) forgotten wallets,
- hardware problems (hard drive containing keys dies or is damaged)
- Bitcoin burning (set up a wallet with no known private key, and it can be seen online, complete with every transaction, but the funds will likely never be retrieved),
- send Bitcoins to invalid address (e.g. Bitcoin Address 1CounterpartyXXXXXXXXXXXXXXXUWLpVr),
- use Bitcoin to send data (document ownership, ID, driver’s license, etc – Why New Forms of Spam Could Bloat Bitcoin’s Block Chain)
Sometimes, not only individuals but also experienced companies make big mistakes and loose their Bitcoins. For example, Bitomat lost private keys to 17,000 of their customers’ Bitcoins. Parity lost $300m of cryptocurrency due to several bugs. And most recently, more than $500 million worth of digital coins were stolen from Coincheck.
Lot Bitcoin losses also come from Bitcoin’s earliest days, when mining rewards were 50 Bitcoins a block, and Bitcoin was trading at less than 1 cent. At that time, many didn’t care if they lost their (private) keys or just forgot about them; this guys threw away his hard drive containing 7500 Bitcoins.
Let’s briefly analyse Bitcoin’s creation and increase of supply. The theoretical total number of Bitcoins is 21 million. Hence, Bitcoin has a controlled supply. Bitcoin protocol is designed in such a way that new Bitcoins are created at a decreasing and predictable rate. Each year, number of new Bitcoins created is automatically halved until Bitcoin issuance halts completely with a total of 21 million Bitcoins in existence.
While the number of Bitcoins in existence will never exceed 21 million, the money supply of Bitcoin can exceed 21 million due to fractional-reserve banking.
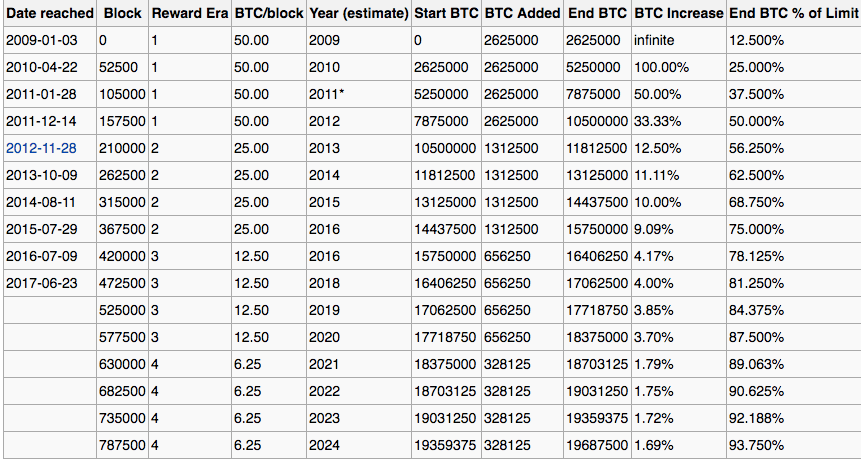
Source: en.bitcoin.it
As of June 23, 2017, Bitcoin has reached a total circulation amount of 16.4 million Bitcoins, which is about 81,25% of the total amount of 21 million Bitcoins.
2017 research by Chainanalysis showed that between 2.78 million and 3.79 million Bitcoins are already lost or 17% – 23% of what’s been mined to date.

How much Bitcoin exactly has been lost? It’s a pretty tough question considering there is no definitive metric for finding the answer. A good estimate is around 25% of all Bitcoin, according to this analysis (this research concludes 30% of all coins had been lost, equating to 25% of all coins when adjusted for the current amount of coins in circulation, which can be done as bulk of lost Bitcoins originate from very early and as Bitcoin’s value has been going up, people lose their coins at a slower rate).
With advent of quantum computers, future of Bitcoin might be perilous. One researcher suggested that quantum computers can calculate the private key from the public one in a minute or two. By learning all the private keys, someone would have access to all available bitcoin. However, a more extensive research shows that in short term, impact of quantum computers will appear to be rather small for mining, security and forking aspects of Bitcoin.
It’s possible that an arms race between quantum hackers and quantum Bitcoin creators will take place. There is an initiative that already tested a feasibility of quantum-safe blockchain platform utilizing quantum key distribution across an urban fiber network.
The below image shows encryption algorithms vulnerable and secure for quantum computing.

Source: cryptomorrow.com
And while work is still ongoing, three quantum-secure methods have been proposed as alternative encryption methodologies for the quantum computing age: lattice-based cryptography, code-based cryptography, multivariate cryptography. IOTA already deploys Winternitz One-Time Signature (OTS) scheme using Lamport signatures, claiming to be resistant to quantum computer algorithms if they have large hash functions.
The no-cloning theorem will make it impossible to copy and distribute a decentralized ledger of qubits (quantum units of information). As qubits can’t be copied or non-destructively read, they will act more like real coins (no issue of double-spending). Quantum Bitcoin miners might support the network by doing operations which amount to quantum error correction (which might replace current Proof-of-Work or Proof-of-Stake systems) as the use of quantum entanglement will enable all network participants to simultaneously agree on a measurement result without a proof of work system.
And while we are waiting for quantum-era Satoshi to rise, check out this THEORETICAL account of how quantum computers may potentially create Bitcoin, which also contains primers on quantum computers and Bitcoin mining.
P.S. Satoshi is estimated to be in the possession of over one million coins




