Let’s start by setting up a context of just how much it costs to verify one Bitcoin transaction. A report on Motherboard recently calculated that the cost to verify 1 Bitcoin transaction is as much electricity as the daily consumption of 1.6 American Households. Bitcoin network may consume up to 14 Gigawatts of electricity (equivalent to electricity consumption of Denmark) by 2020 with a low estimate of 0.5GW.
There is much written about theft of Bitcoin, as people are exposed to cyber criminals, but there are also instances where people are losing their coins. In case of loss, it’s almost always impossible to recover lost Bitcoins. They then remain in the blockchain, like any other Bitcoin, but are inaccessible because it’s impossible to find private keys that would allow them to be spent again.
Bitcoin can be lost or destroyed through the following actions:
- irrecoverable passwords or private keys, b) forgotten wallets,
- hardware problems (hard drive containing keys dies or is damaged)
- Bitcoin burning (set up a wallet with no known private key, and it can be seen online, complete with every transaction, but the funds will likely never be retrieved),
- send Bitcoins to invalid address (e.g. Bitcoin Address 1CounterpartyXXXXXXXXXXXXXXXUWLpVr),
- use Bitcoin to send data (document ownership, ID, driver’s license, etc – Why New Forms of Spam Could Bloat Bitcoin’s Block Chain)
Sometimes, not only individuals but also experienced companies make big mistakes and loose their Bitcoins. For example, Bitomat lost private keys to 17,000 of their customers’ Bitcoins. Parity lost $300m of cryptocurrency due to several bugs. And most recently, more than $500 million worth of digital coins were stolen from Coincheck.
Lot Bitcoin losses also come from Bitcoin’s earliest days, when mining rewards were 50 Bitcoins a block, and Bitcoin was trading at less than 1 cent. At that time, many didn’t care if they lost their (private) keys or just forgot about them; this guys threw away his hard drive containing 7500 Bitcoins.
Let’s briefly analyse Bitcoin’s creation and increase of supply. The theoretical total number of Bitcoins is 21 million. Hence, Bitcoin has a controlled supply. Bitcoin protocol is designed in such a way that new Bitcoins are created at a decreasing and predictable rate. Each year, number of new Bitcoins created is automatically halved until Bitcoin issuance halts completely with a total of 21 million Bitcoins in existence.
While the number of Bitcoins in existence will never exceed 21 million, the money supply of Bitcoin can exceed 21 million due to fractional-reserve banking.
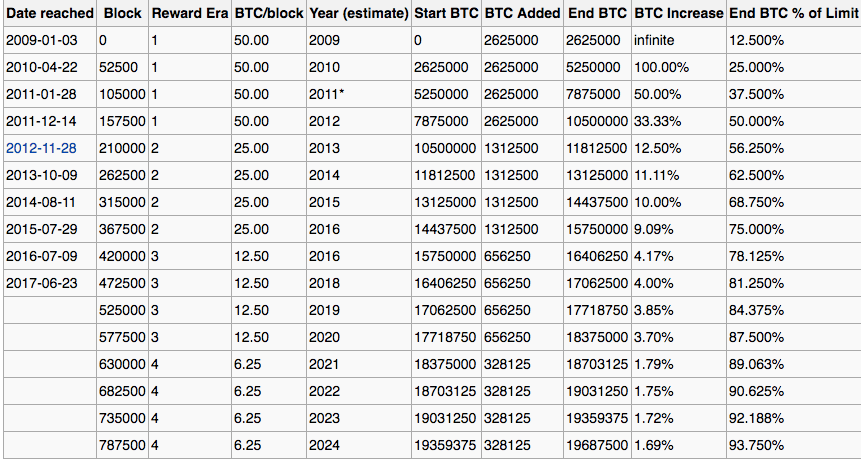
Source: en.bitcoin.it
As of June 23, 2017, Bitcoin has reached a total circulation amount of 16.4 million Bitcoins, which is about 81,25% of the total amount of 21 million Bitcoins.
2017 research by Chainanalysis showed that between 2.78 million and 3.79 million Bitcoins are already lost or 17% – 23% of what’s been mined to date.

How much Bitcoin exactly has been lost? It’s a pretty tough question considering there is no definitive metric for finding the answer. A good estimate is around 25% of all Bitcoin, according to this analysis (this research concludes 30% of all coins had been lost, equating to 25% of all coins when adjusted for the current amount of coins in circulation, which can be done as bulk of lost Bitcoins originate from very early and as Bitcoin’s value has been going up, people lose their coins at a slower rate).
With advent of quantum computers, future of Bitcoin might be perilous. One researcher suggested that quantum computers can calculate the private key from the public one in a minute or two. By learning all the private keys, someone would have access to all available bitcoin. However, a more extensive research shows that in short term, impact of quantum computers will appear to be rather small for mining, security and forking aspects of Bitcoin.
It’s possible that an arms race between quantum hackers and quantum Bitcoin creators will take place. There is an initiative that already tested a feasibility of quantum-safe blockchain platform utilizing quantum key distribution across an urban fiber network.
The below image shows encryption algorithms vulnerable and secure for quantum computing.

Source: cryptomorrow.com
And while work is still ongoing, three quantum-secure methods have been proposed as alternative encryption methodologies for the quantum computing age: lattice-based cryptography, code-based cryptography, multivariate cryptography. IOTA already deploys Winternitz One-Time Signature (OTS) scheme using Lamport signatures, claiming to be resistant to quantum computer algorithms if they have large hash functions.
The no-cloning theorem will make it impossible to copy and distribute a decentralized ledger of qubits (quantum units of information). As qubits can’t be copied or non-destructively read, they will act more like real coins (no issue of double-spending). Quantum Bitcoin miners might support the network by doing operations which amount to quantum error correction (which might replace current Proof-of-Work or Proof-of-Stake systems) as the use of quantum entanglement will enable all network participants to simultaneously agree on a measurement result without a proof of work system.
And while we are waiting for quantum-era Satoshi to rise, check out this THEORETICAL account of how quantum computers may potentially create Bitcoin, which also contains primers on quantum computers and Bitcoin mining.
P.S. Satoshi is estimated to be in the possession of over one million coins


Nowadays, ‘artificial intelligence’ (AI) and ‘machine learning’ (ML) are cliches that people use to signal awareness about technological trends. Companies tout AI/ML as panaceas to their ills and competitive advantage over their peers. From flower recognition to an algorithm that won against Go champion to big financial institutions, including ETFs of the biggest hedge fund in the world are already or moving to the AI/ML era.
However, as with any new technological breakthroughs, discoveries and inventions, the path is laden with misconceptions, failures, political agendas, etc. Let’s start by an overview of basic methodologies of ML, the foundation of AI.
101 and limitations of AI/ML
The fundamental goal of ML is to generalise beyond specific examples/occurrences of data. ML research focuses on experimental evaluation on actual data for realistic problems. ML’s performance is then evaluated by training a system (algorithm, program) on a set of test examples and measuring its accuracy at predicting the novel test (or real-life) examples.
Most frequently used methods in ML are induction and deduction. Deduction goes from the general to the particular, and induction goes from the particular to the general. Deduction is to induction what probability is to statistics.
Let’s start with induction. Domino effect is perhaps the most famous instance of induction. Inductive reasoning consists in constructing the axioms (hypotheses, theories) from the observation of supposed consequences of these axioms.Induction alone is not that useful: the induction of a model (a general knowledge) is interesting only if you can use it, i.e. if you can apply it to new situations, by going somehow from the general to the particular. This is what scientists do: observing natural phenomena, they postulate the laws of Nature. However, there is a problem with induction. It’s impossible to prove that an inductive statement is correct. At most can one empirically observe that the deductions that can be made from this statement are not in contradiction with experiments. But one can never be sure that no future observation will contradict the statement. Black Swam theory is the most famous illustration of this problem.
Deductive reasoning consists in combining logical statements (axioms, hypothesis, theorem) according to certain agreed upon rules in order to obtain new statements. This is how mathematicians prove theorems from axioms. Proving a theorem is nothing but combining a small set of axioms with certain rules. Of course, this does not mean proving a theorem is a simple task, but it could theoretically be automated.
A problem with deduction is exemplified by Gödel’s theorem, which states that for a rich enough set of axioms, one can produce statements that can be neither proved nor disproved.
Two other kinds of reasoning exist, abduction and analogy, and neither is frequently used in AI/ML, which may explain many of current AI/ML failures/problems.
Like deduction, abduction relies on knowledge expressed through general rules. Like deduction, it goes from the general to the particular, but it does in an unusual manner since it infers causes from consequences. So, from “A implies B” and “B”, A can be inferred. For example, most of a doctor’s work is inferring diseases from symptoms, which is what abduction is about. “I know the general rule which states that flu implies fever. I’m observing fever, so there must be flu.” However, abduction is not able to build new general rules: induction must have been involved at some point to state that “flu implies fever”.
Lastly, analogy goes from the particular to the particular. The most basic form of analogy is based on the assumption that similar situations have similar properties. More complex analogy-based learning schemes, involving several situations and recombinations can also be considered. Many lawyers use analogical reasoning to analyse new problems based on previous cases. Analogy completely bypasses the model construction: instead of going from the particular to the general, and then from to the general to the particular, it goes directly from the particular to the particular.
Let’s next check some of conspicuous failures in AI/ML (in 2016) and corresponding AI/ML methodology that, in my view, was responsible for failure:
Microsoft’s chatbot Tay utters racist, sexist, homophobic slurs (mimicking/analogising failure)
In an attempt to form relationships with younger customers, Microsoft launched an AI-powered chatbot called “Tay.ai” on Twitter in 2016. “Tay,” modelled around a teenage girl, morphed into a “Hitler-loving, feminist-bashing troll“—within just a day of her debut online. Microsoft yanked Tay off the social media platform and announced it planned to make “adjustments” to its algorithm.
AI-judged beauty contest was racist (deduction failure)
In “The First International Beauty Contest Judged by Artificial Intelligence,” a robot panel judged faces, based on “algorithms that can accurately evaluate the criteria linked to perception of human beauty and health.” But by failing to supply the AI/ML with a diverse training set, the contest winners were all white.
Chinese facial recognition study predicted convicts but shows bias (induction/abduction failure)
Researchers in China’s published a study entitled “Automated Inference on Criminality using Face Images.” They “fed the faces of 1,856 people (half of which were convicted violent criminals) into a computer and set about analysing them.” The researchers concluded that there were some discriminating structural features for predicting criminality, such as lip curvature, eye inner corner distance, and the so-called nose-mouth angle. Many in the field questioned the results and the report’s ethics underpinnings.
Concluding remarks
The above examples must not discourage companies to incorporate AI/ML into their processes and products. Most AI/ML failures seem to stem from band-aid, superfluous way of embracing AI/ML. A better and more sustainable approach to incorporating AI/ML would be to initiate a mix of projects generating both quick-wins and long-term transformational products/services/process. For quick-wins, a company might focus on changing internal employee touchpoints, using recent advances in speech, vision, and language understanding, etc.
For long-term projects, a company might go beyond local/point optimisation, to rethinking business lines, products/services, end-to-end processes, which is the area in which companies are likely to see the greatest impact. Take Google. Google’s initial focus was on incorporating ML into a few of their products (spam detection in Gmail, Google Translate, etc), but now the company is using machine learning to replace entire sets of systems. Further, to increase organisational learning, the company is dispersing ML experts across product groups and training thousands of software engineers, across all Google products, in basic machine learning.