
Poker is a game with imperfect information. Imperfect-information games model settings where players have private information. Huge progress has been made in solving such games over the past 20 years, especially since the Annual Computer Poker Competition was established in 2006. Before 2006, general-purpose linear programming solvers (example) and sequence-form representation (example) were used to solve small variants of poker or coarse abstractions of two-player limit Texas Hold’em.
Since 2006, two more scalable equilibrium-finding algorithms and problem representations have been developed for two-player zero-sum games. One family is based on smoothed gradient descent algorithms and a decomposed problem representation. The other family, counterfactual regret minimisation (CFR), is based on a form of self-play using no-regret learning, adapted so that regret updates can be computed at each information set separately, instead of requiring regrets to be updated for entire game strategies.
Best available guarantees for CFR require ~1/ε 2 iterations over the game tree to reach an ε-equilibrium, that is, strategies for players such that no player can be exploited by more than ε by any strategy. The gradient-based algorithms require only ~1/ε or ~log(1/ε) iterations. The latter approach matches the optimal number of iterations required. On the other hand, more effective sampling techniques have been developed for CFR than for the gradient-based algorithms, so quick approximate iterations can be used.
How to solve imperfect-information games
Currently, the main approach for solving imperfect-information games is shown in the image below. First, the game is abstracted to generate a smaller but strategically similar game, reducing it to a size that can be tackled with an equilibrium finding algorithm.
Then, the abstract game is solved for equilibrium or near-equilibrium. Nash equilibrium defines a notion of rational play, i.e. it’s a profile of strategies, one per player, such that no player can increase his/her expected payoff by switching to a different strategy. A strategy for a player states for each information set where it is the player’s turn, the probability with which the player should select each of his/her available actions.
An information set is a collection of game states that cannot be distinguished by the player whose turn it is because of private information of other players. Finally, the strategies from the abstract game are mapped back to the original game.
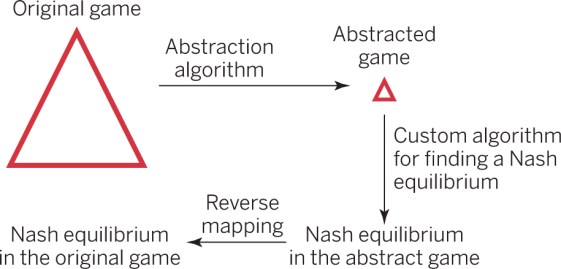
Two main kinds of abstraction are used. One is information abstraction, where it is assumed in the abstract game that a player does not know some information that he/she actually knows. Lossless abstraction algorithms yield an abstract game from which each equilibrium is also an equilibrium in the original game, and typically reduce the size of poker (or other such) games by 1-2 orders of magnitude.
The second method, action abstraction, removes some actions from consideration in the abstract game, and is useful when the number of actions that a player can choose is large.
Libratus vs. top poker players
Previously, AI has beaten chess, checkers, Go, Jeopardy but managed to beat poker only in January 2017. Unlike chess or Go, poker is a game of imperfect-information and requires a different methodology to tackle it.
In a 20-day competition involving 120,000 hands at Rivers Casino in Pittsburgh during January 2017, Libratus became the first AI to defeat top human players at Heads-up no-limit Texas Hold’em—the primary benchmark and long-standing challenge problem for imperfect-information game-solving by AIs.
Libratus beat a team of four top poker professionals in Heads-up no-limit Texas hold’em, which has 6.38 × 10161 decision points. It played with each player a two-player game and collectively amassed about $1.8 million in chips. It used the above-mentioned approach of simplifying and abstracting the game, then finding an equilibrium followed by mapping the abstract game back to the original one while adding details and improving the overall strategy. Libratus includes three main parts:
- Algorithm for computing (an approximate Nash equilibrium) a blueprint for the overall strategy of smaller and simpler play, using a precomputed decision tree of about 1013 decision points, instead of 10161 points in the usual game. So it starts with a simple weighted decision tree from which to select its moves depending on its hole cards and those on the board. One example of these simpler abstractions is grouping and treating similarly hands such as King-high flush and a Queen-high flush or bets of $100 or $105.
- Algorithm that fleshes out the details of the strategy for earlier subgames that are reached or realised during a play, and a coarse strategy for the later rounds based on assumed realization of the earlier ones. Whenever an opponent makes a move that is not in the abstraction, the module computes a solution to this subgame that includes the opponent’s move.
- Self-improver algorithm that solves potential weaknesses opponents have identified in the game’s strategy. Typically, AIs use ML to find mistakes in the opponent’s strategy and exploit them. But that also opens the AI to exploitation if the opponent shifts strategy. Instead, Libratus’ self-improver module analyses opponents’ bet sizes to detect potential holes in Libratus’ strategy. Libratus then adds these missing decision branches, computes probabilities and strategies for them, and adds them to the existing strategy.
This strategy is called the blueprint strategy.
Libratus is computationally expensive and was powered by the Bridges system, a high-performance computer that could achieve, at maximum, 1.35 Pflops. Libratus burned through approximately 19 million core hours of computing throughout the tournament In addition to beating the human experts, Libratus has also won against the previous AI champion Baby Tartanian8.
Another one, DeepStack, is an AI capable of playing Heads-up no-limit Texas Hold’em, which includes a similar algorithm, continual re-solving, but it has not been tested against top professional players.
Most of the same abstraction techniques apply for games with more than two players that are not zero-sum, but their equilibrium-finding problems are such that no polynomial-time algorithm is known. It is not even clear that finding a Nash equilibrium is the right goal in such games. Different equilibria can have different values to the players.
This AI could be used for calculating strategic decisions in the real world, such as in finance and information security.